
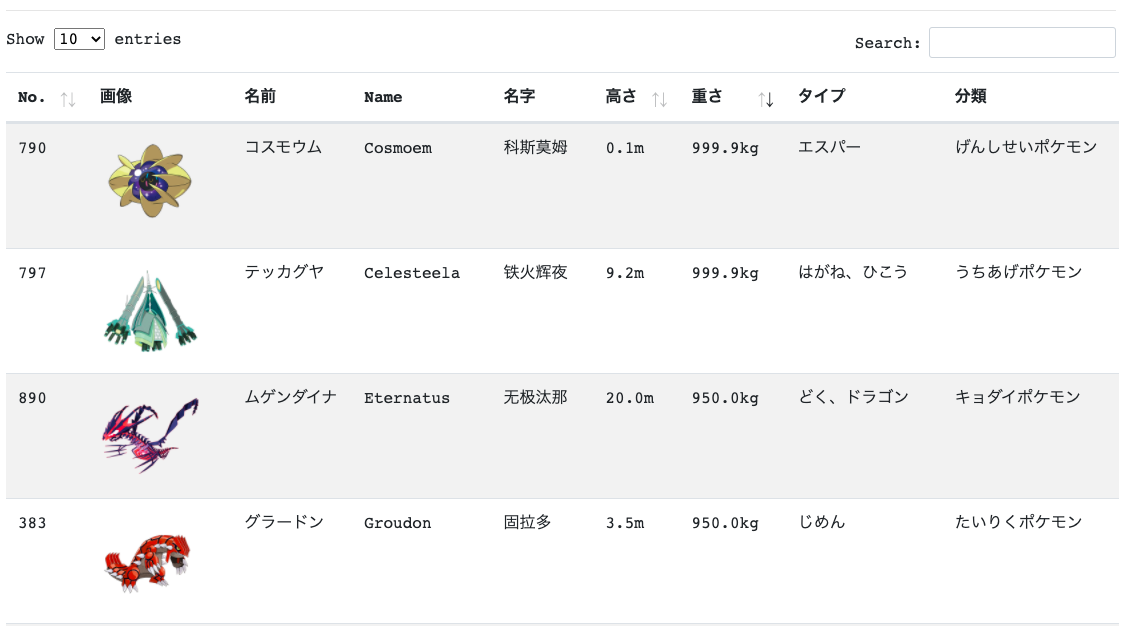
Flask+Pandas+DataTablesで作ったポケモン一覧表
ポケモン全然詳しくないので、もっと詳しくなろうという気持ちが強くて
Pokédex みたいなものでも作ろうかと思った。
ここ で見られる。
最も重いポケモンは 999.9kg ですね。
スクレイピング
まずはスクレイピングで必要なデータを取得。
requests を使うのはもはや常套手段ですが、今回は asyncio と aiohttp を使って非同期スクレイピングを行う。
画像は ポケモンずかん で取得、 他は PokéAPI という RESTful API を使って、必要な情報を JSON ファイルとして保存。
asyncio と aiohttp について、以下は画像収集の例となる。 全ポケモンはかなりの量なので、semaphore を使って、リクエスト数を制限する。
async def download_image(sess, no, url):
async with sess.get(url) as resp:
with open(no + '.png', 'wb') as img:
img.write(await resp.read())
async def limited_download(sess, no, url, limit):
async with limit:
return await download_image(sess, no, url)
async def image_downloader(img_urls):
tasks = []
limit = asyncio.Semaphore(100)
async with aiohttp.ClientSession() as sess:
for no, url in img_urls.items():
tasks.append(
asyncio.ensure_future(limited_download(sess, no, url, limit)))
await asyncio.gather(*tasks)
if __name__ == '__main__':
img_urls = get_image_url()
loop = asyncio.get_event_loop()
start = datetime.now()
loop.run_until_complete(image_downloader(img_urls))
end = datetime.now()
print(end - start)テーブルとしてレンダリング
データ収集完了後、さっさと綺麗に表示されたいなら、DataTables という jQuery プラグインを使うのが便利です。
サーバ側からデータを取得したいので、Server-side processing を使用する。
画像は columnDefs の設定によって表示される。
$(document).ready(function () {
$('#data').DataTable({
ajax: "api/pokemon",
serverSide: true,
columns: [
{data: 'id'},
{data: 'image', orderable: false, searchable: false},
...
],
columnDefs: [
{ targets: 1,
render: function(data) {
return '<img src="'+data+'" width="100">'
}
}
]
});
});サーバ側は Pandas を使って、JSON データを DataFrame として読み込ませる。
Pagination、検索、ソートを自ら処理することが必要です。
DataTablesから送信した query string
order[0][column]: 0
order[0][dir]: asc
start: 0
length: 10
search[value]:
search[regex]: false
- start と length は Pagination に対応。
- search[value] は検索で、search[regex] を true にすれば、正規表現でも使える。
- order[0][column]: 並べ替える列のindex
- order[0][dir]: asc か desc
Flask と Pandas で処理すると、こんな感じ。
total = len(df.index)
filtered = len(df.index)
search = request.args.get('search[value]')
start = request.args.get('start', type=int, default=0)
length = request.args.get('length', type=int, default=10)
end = start + length
col_idx = request.args.get('order[0][column]')
col_name = request.args.get(f'columns[{col_idx}][data]')
order_allowed = ['id', 'height', 'weight']
if col_name not in order_allowed:
col_name = 'id'
order = request.args.get(f'order[0][dir]')
if search:
target = df[df.columns[~df.columns.isin(['id', 'image'])]]
df_filtered = df[target.apply(
lambda col: col.str.contains(search, na=False)).any(axis=1)
].reset_index(drop=True)
filtered = len(df_filtered.index)
df_filtered = order_by(df_filtered, order, col_name)
poke = df_filtered.iloc[start:end]
else:
_df = order_by(df, order, col_name)
poke = _df.iloc[start:end]
cols = ['id', 'image', 'name_jp', 'name_en', 'name_cn',
'height', 'weight', 'types', 'genus']
res = []
for key, value in poke.iterrows():
row = {col: value[col] for col in cols}
res.append(row)
return {
'data': res,
'draw': request.args.get('draw', type=int),
'recordsTotal': total,
'recordsFiltered': filtered
}デプロイ
uWSGI + Nginx でデプロイする。
で、uWSGI と Nginx の設定が終わって、動いてみたら、
502 Bad Gateway が出た。
Nginx のエラーログ /var/log/nginx/error.log を見ると、
[error] 124922#124922: *6 recv() failed (104: Connection reset by peer) while reading response header from upstream
uWSGI との通信で何か問題が発生したみたいです。
原因は uWSGI の buffer-size はデフォルト値 4096 になったので、uWSGIの設定ファイル uwsgi.ini で buffer-size を設定する必要がある。